解決方案與應用
全方位人工智慧解決方案
人工智慧(AI,Artificial Intelligence)的應用無所不在,功能上取得了重大進展,許多引人注目的應用正在改變世界。無論在醫療保健、金融科技或零售領域,您都可以看到人工智慧在這些產業中發揮重要作用。另一方面,搭載AI功能的產品正在影響世界,好比AI手機、AI電腦、AI Pins、Rabbit R1等,這些產品則是由AI引擎所驅動著。
如何釋放這些AI產品的力量?秘密在於LLM(大型語言模型)和LAM(大型動作模型)。如果沒有LLM和LAM,由人工智慧驅動的產品就無法釋放AI的能力給終端用戶。LLM與LAM會使用強大的人工智慧伺服器進行訓練,這些伺服器通常位於AI資料中心裡。
AI資料中心由AI伺服器、高容量交換器、收發器與電纜組成,缺一不可。
AI的流量具有以下特點。

高頻寬和高擴展性
無損傳輸
遙測(監控)
負載平衡
從傳統網路轉向基於AI的網路是一種改變網路運作方式的演進。在 AI/ML 叢集中,作業完成時間 (JCT) 是最重要的指標。
如何加速工作完成時間

低延遲
負載平衡

無損網路
當我們談論AI網路時,RoCE(RDMA over Converged Ethernet,基於融合乙太網的 RDMA 加速)發揮著重要作用。由於AI網路中的無損很重要,因此RoCE能控制傳輸速率和流量擁塞。
什麼是 RDMA(Remote Direct Memory Access,遠端直接記憶體存取)? RDMA 是一種能夠在記憶體和周邊設備之間或從記憶體到記憶體之間傳輸資料的技術,無需涉及CPU 或作業系統資源。存取網路卡記憶體時則使用UDP堆疊的緩衝區來減少處理負擔,減少延遲並實現更高的吞吐量。
網路中的PFC(Priority-based Flow Control,優先順序流程控制)和ECN(Explicit Congestion Notification,明確擁塞通知)則能協助實現無損傳輸和避免擁塞。PFC和ECN的結合就是DCQCN(Data Center Quantized Congestion Notification,資料中心量化擁塞通知),它是AI網路的高效能擁塞管理解決方案,DCQCN是RoCEv2網路中使用最廣泛的擁塞控制演算法。

GPU(Graphic Processing Unit,圖形處理器)最初設計用於加速電腦圖形和影像像素處理。如今,科學家發現GPU在資料科學和影像分析方面表現出色,它們的應用範圍也更廣泛,包括AI和ML(Machine Learning,機器學習),這就是為什麼GPU現在被稱為GPGPU(General-Purpose computing on Graphics Processing Unit,通用圖形處理器)。當 GPU 與 CPU 協同工作時,它們可以加速工作流程並釋放人工智慧的力量。




為什麼選擇鈺登科技AI解決方案
一個設計良好的AI資料中心應該考慮GPU架構、GPU特性、總成本和功耗。鈺登科技的AI解決方案經最佳化後具高性能和高效率,在高負載環境中表現出色。
鈺登科技尖端的AI/ML交換器和伺服器由世界一流的晶片供應商提供晶片,並由我們經驗豐富的工程師設計,可以最大化計算效率。此外,鈺登科技還提供即插即用的收發器和電纜,經過嚴格的驗證,與鈺登科技交換器運作順暢,您無需擔心相容性問題。
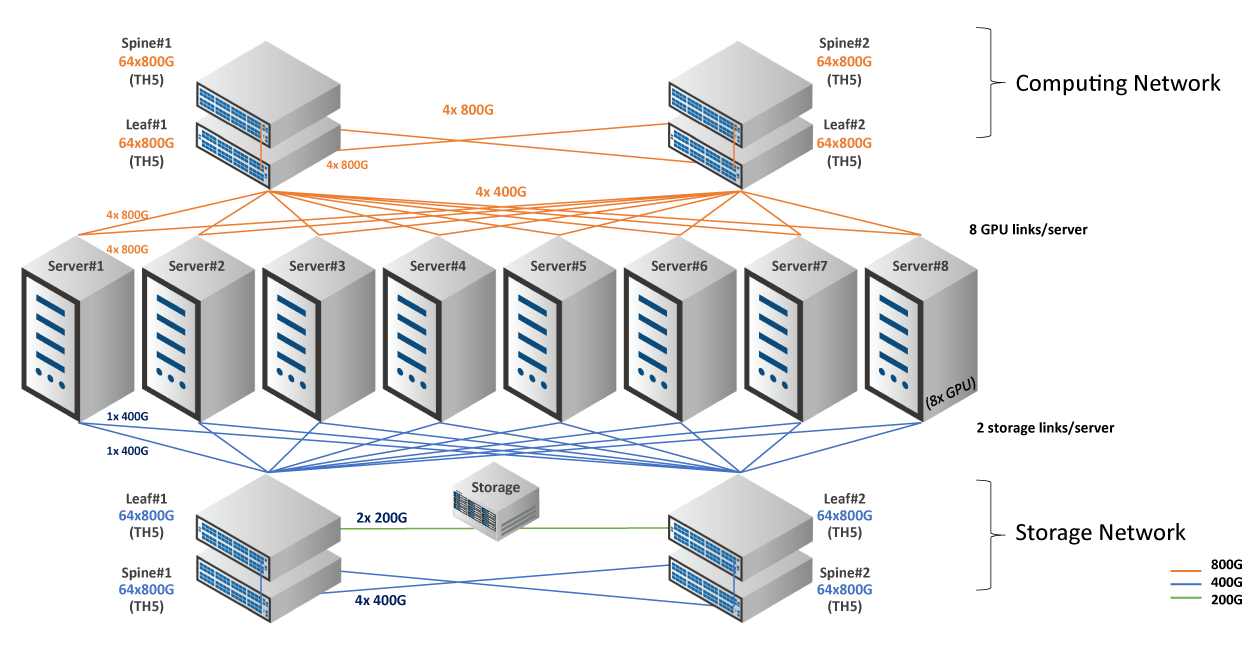
同時,我們採用開放式架構,主動參與不同的項目,然後為您的 AI/ML 連接需求提供完整、靈活且面向未來的解決方案。
鈺登科技始終走在市場前面。從邊緣到核心,從交換器到伺服器,現在鈺登科技為客戶提供建構人工智慧資料中心所需的一切,人工智慧資料中心特別適合用於進行深度學習、訓練和推理的任務。


相關產品

▌800G QSFP112-DD-2xDR4 500m ▌SMF ▌波長(nm):1310 ▌傳輸距離:500m

▌800G QSFP112-DD 2xFR4 2km ▌SMF ▌波長(nm):1310 ▌傳輸距離:2km

▌800G OSFP SR8 50m ▌OM4 ▌波長(nm):850 ▌傳輸距離:50m

▌800G OSFP 2xSR4 50m ▌OM4 ▌波長(nm):850 ▌傳輸距離:50m

▌800G OSFP-2xFR4 2km ▌SMF ▌波長(nm):1310 CWDM ▌傳輸距離:2km

▌800G OSFP-2xDR4 500m ▌SMF ▌波長(nm):1310 ▌傳輸距離:500m