Решения и области применения
Комплексное решение в области искусственного интеллекта
Искусственный интеллект применяется повсеместно и достиг значительного прогресса. Множество необычных ярких продуктов и приложений ИИ меняют мир. Искусственный интеллект играет важную роль в самых разных отраслях, будь то здравоохранение, финансы или розничная торговля. С другой стороны, продукты с аббревиатурой ИИ в названии оказывают влияние на мир: ИИ-телефоны, ИИ-компьютеры, устройства типа AI pin, Rabbit R1 и другие, управляются ИИ-движками.
Как раскрыть все возможности этих ИИ-продуктов? Секрет кроется в больших языковых моделях (Large Language Model, LLM) и больших моделях действий (Large Action Model, LAM). Без LLM и LAM ИИ-продукты не смогут донести магию ИИ до конечных пользователей. Эти модели обучаются с помощью мощных серверов ИИ, которые обычно располагаются в центрах обработки данных ИИ.
Центр обработки данных ИИ невозможно представить без высокопроизводительных коммутаторов, трансиверов и кабелей.
ИИ-трафик имеет следующие особенности.

Большая пропускная способность и высокая масштабируемость
Передача данных без потерь
Телеметрия (мониторинг)
Балансировка нагрузки
Переход от традиционной сети к ИИ-сети требует изменения принципов работы сети. В кластерах искусственного интеллекта (AI) и машинного обучения (ML) самой важной метрикой является время выполнения заданий (JCT).
Как сократить время выполнения заданий

Низкая задержка
Балансировка нагрузки

Сеть без потерь
Протокол RoCE (RDMA over Converged Ethernet) играет важную роль в сетях искусственного интеллекта. Поскольку отсутствие потерь в таких сетях имеет большое значение, RoCE контролирует скорость передачи данных и перегрузку по трафику.
Что такое RDMA (удаленный прямой доступ к памяти)? Технология RDMA позволяет передавать данные между памятью и периферийными устройствами или из памяти в память без привлечения ресурсов процессора или ОС. При реализации RDMA через Ethernet отправитель напрямую обращается к памяти карты NIC из приложения, а драйвер NIC использует буфер стека UDP для снижения затрат на обработку, уменьшения задержек и достижения более высокой пропускной способности.
Функции управления потоком на основе приоритета (PFC) и явного уведомления о перегруженности (ECN) в сети предотвращают потерю данных и перегрузки. Вместе PFC и ECN обеспечивают функцию уведомлений о перегрузках ЦОД с квантованной обратной связью (DCQCN), высокопроизводительное решение для управления перегрузками в сетях искусственного интеллекта. DCQCN — наиболее популярный алгоритм управления перегрузками в сетях RoCEv2.

Графические процессоры (GPU) изначально были разработаны для ускорения компьютерной графики и обработки пикселей изображений. В наши дни ученые обнаружили, что графические процессоры превосходно справляются с наукой о данных и анализом изображений, они также применяются в более широком диапазоне, включая AI и ML (машинное обучение), и именно поэтому графический процессор теперь является так называемым GPGPU (общий). Целевые вычисления на графическом процессоре). Когда графические процессоры взаимодействуют с центральными процессорами, они могут ускорить рабочий процесс и раскрыть возможности искусственного интеллекта.

Edgecore предлагает коммутатор NOS с поддержкой AI, SONiC, который поддерживается на широком спектре платформ коммутации, обеспечивая интерфейс абстракции коммутатора (SAI) в диапазоне от 1G до 800G, охватывающий leaf и коммутаторы уровня суперпозвоночника.
Благодаря универсальным коммутаторам SONiC и Edgecore поддерживаются телеметрический мониторинг и управление, оптимизированная пропускная способность за счет точной настройки сети без потерь и балансировки нагрузки. Все эти функции предназначены для уменьшения перегрузок, точного определения точек перегрузки, оптимизации распределения нагрузки и JCT.
Кроме того, Edgecore обеспечивает комплексное обслуживание и поддержку SONiC на разных этапах, включая предпродажное и послепродажное обслуживание.
Основные преимущества решения

Планирование и проектирование
Обеспечение мобильности

Поддержка по работе с оборудованием

Поддержка по работе с ПО
Преимущества решений Edgecore для искусственного интеллекта
Правильно спроектированный ЦОД для задач искусственного интеллекта должен учитывать архитектуру и характеристики GPU, общую стоимость и энергопотребление. Решения Edgecore для ИИ оптимизированы для обеспечения высокой производительности и эффективности, и отлично работают в условиях высоких нагрузок.
Передовые AI/ML коммутаторы и серверы Edgecore работают на чипсетах ведущих мировых производителей и разработаны нашими опытными инженерами, чтобы максимально повысить эффективность вычислений. Кроме того, Edgecore предлагает подключаемые трансиверы и кабели, полностью совместимые с коммутаторами Edgecore, что подтверждено тщательным тестированием. Вы можете не беспокоиться о совместимости.
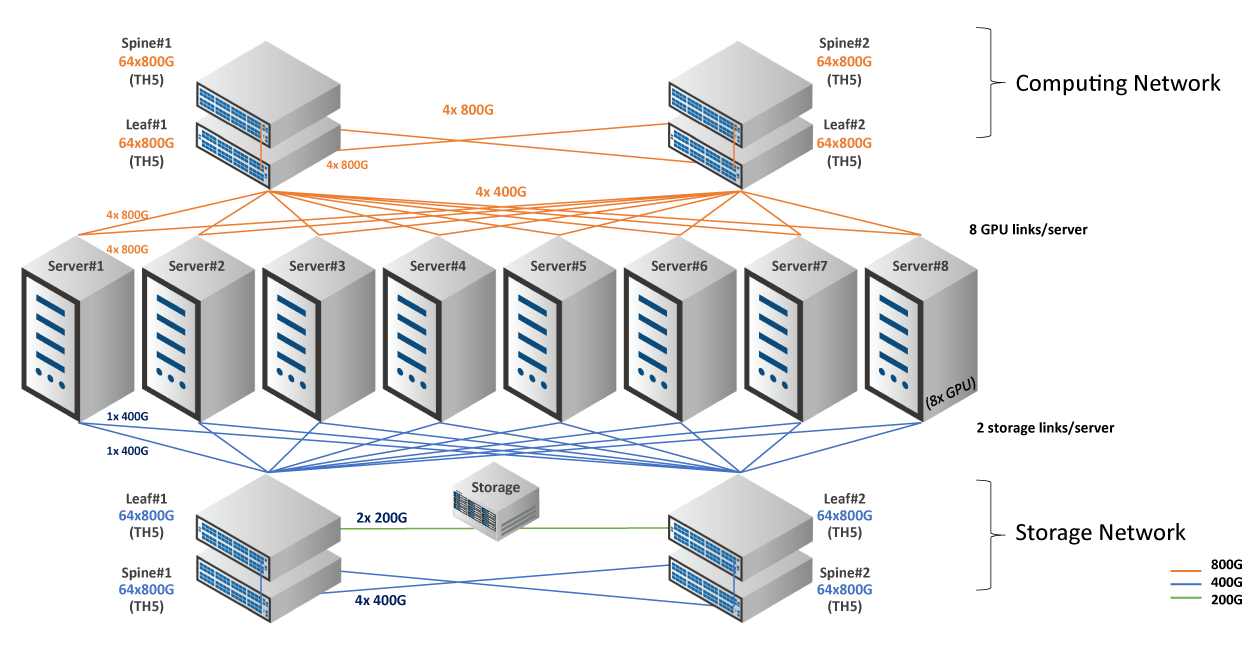
При этом мы используем открытую архитектуру, активно привлекаем различные проекты и поставляем комплексные, гибкие и перспективные решения для ваших потребностей в подключении для задач искусственного интеллекта и машинного обучения.
Edgecore всегда опережает рынок. От границы до ядра сети, от коммутатора до сервера — сегодня Edgecore поставляет своим клиентам все, что необходимо для создания ЦОД ИИ, идеально подходящего для глубокого обучения, тренировки ИИ и инференса.

Информационный документ по искусственному интеллекту и машинному обучению

Ускорьте свою сеть искусственного интеллекта прямо сейчас!
Подходящие продукты
Edgecore AGS8600 — это высокопроизводительный масштабируемый сервер на базе графического процессора, подходящий для приложений искусственного интеллекта/машинного обучения и высокопроизводительных вычислений. Сервер идеально подходит для обучения больших языковых моделей, автоматизации, классификации и распознавания объектов. Он оснащен восемью процессорами AMD Instinct MI325X и двумя процессорами AMD EPYC 9005/Turin.
Edgecore AGS8600 — это высокопроизводительный масштабируемый сервер на базе графического процессора, подходящий для приложений искусственного интеллекта/машинного обучения и высокопроизводительных вычислений. Сервер идеально подходит для обучения больших языковых моделей, автоматизации, классификации и распознавания объектов. Он оснащен восемью процессорами AMD Instinct MI325X и двумя процессорами AMD EPYC 9005/Turin.
APS800-16O 16 портов OSFP800 800G, каждый из которых может быть преобразован в 2x400G, 4x200G или 8x100G. SerDes поддерживает работу на скоростях 10G, 25G, 50G и 100G.
AS9817-64O: 64 порта коммутации OSFP800 с Tomahawk 5. Высокопроизводительный коммутатор с низкой задержкой для высокопроизводительных центров обработки данных.
AS9817-64D: 64 порта коммутации QSFP-DD800 с Tomahawk 5. Высокопроизводительный коммутатор с низкой задержкой для высокопроизводительных центров обработки данных.
32 x 800G OSFP800 с Tomahawk 5
 Высокопроизводительный коммутатор с малой задержкой для высокопроизводительных центров обработки данных. Бюджет мощности до 30 Вт на порт.
Высокопроизводительный коммутатор с малой задержкой для высокопроизводительных центров обработки данных. Бюджет мощности до 30 Вт на порт.32 x 800G QSFP-DD800 с Tomahawk 5
Высокопроизводительный коммутатор с малой задержкой для высокопроизводительных центров обработки данных. Бюджет мощности до 30 Вт на порт.

▌800G QSFP112-DD-2xDR4 500 м ▌SMF ▌Длина волны (нм): 1310 ▌Дальность действия: 500 м

▌800G QSFP112-DD 2xFR4 2 км ▌SMF ▌Длина волны (нм): 1310 ▌Дальность действия: 2 км

▌800G OSFP SR8 50 м ▌OM4 ▌Длина волны (нм): 850 ▌Дальность действия: 50 м

▌800G OSFP 2xSR4 50 м ▌OM4 ▌Длина волны (нм): 850 ▌Дальность действия: 50 м

▌800G OSFP-2xFR4 2 км ▌SMF ▌Длина волны (нм): 1310 CWDM ▌Дальность действия: 2 км

▌800G OSFP-2xDR4 500 м ▌SMF ▌Длина волны (нм): 1310 ▌Дальность действия: 500 м