
Page 11 - Edgecore Product Catalogue 2026
P. 11
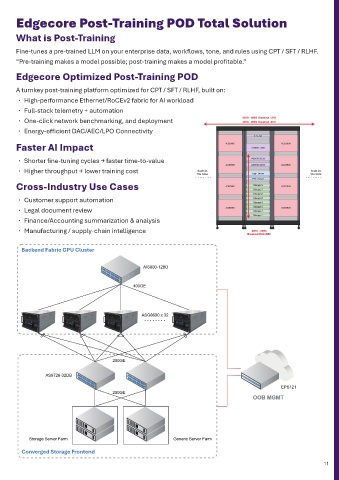
HPC SWITCH Edgecore Post-Training POD Total Solution
The HPC series is designed for extreme-performance computing environments that demand ultra- What is Post-Training
low latency, deterministic throughput, and massive east-west bandwidth. Powered by the Broadcom® Fine-tunes a pre-trained LLM on your enterprise data, workflows, tone, and rules using CPT / SFT / RLHF.
Tomahawk Ultra ASIC, the AIS800-64OU delivers 51.2 Tbps of non-blocking switching capacity with “Pre-training makes a model possible; post-training makes a model profitable.”
64 × 800G OSFP800 high-radix ports, enabling dense, scale-out interconnects for next-generation
supercomputing clusters. Edgecore Optimized Post-Training POD
Driven by an Intel® Xeon® Processor D-1713NTE, the platform offers enhanced programmability, A turnkey post-training platform optimized for CPT / SFT / RLHF, built on:
telemetry, and system control for performance-critical HPC workloads. • High-performance Ethernet/RoCEv2 fabric for AI workload
Engineered for scientific computing, simulation, modeling, and large-scale parallel applications, the • Full-stack telemetry + automation
HPC series provides a resilient, scalable, and power-efficient foundation for modern high-performance • One-click network benchmarking, and deployment
computing fabrics. • Energy-efficient DAC/AEC/LPO Connectivity
NEW Faster AI Impact
• Shorter fine-tuning cycles → faster time-to-value
AIS800-64OU • Higher throughput → lower training cost
64 x 800G OSFP800 ports Cross-Industry Use Cases
51.2 Tbps • Customer support automation
Broadcom® Tomahawk Ultra
Intel® Xeon® Processor D-1713NTE • Legal document review
• Finance/Accounting summarization & analysis
AI DATA CENTER NETWORKING TOPOLOGY • Manufacturing / supply-chain intelligence
The cutting-edge AI/ML-driven switches are designed for advanced networking solutions, featuring Backend Fabric GPU Cluster
intelligent capabilities, real-time analytics, and efficient management, ensuring seamless connectivity in
dynamic environments.
Rail-Optimized Topology for best optimized
Rail-Optimized Topology for best optimized performance of
DDN/LLM performance of AMD MI325X 256 GPU AI cluster
AMD MI325X 256 GPU AI cluster
Spine Switch
AIS800 800G
TH5 (800G)
Rail#1 Rail#2 Rail#3 Rail#4 Rail#5 Rail#6 Rail#7 Rail#8
Leaf Switch
AIS800
TH5 (800G)
400G
AMD MI325X
GPU Servers
NIC X8 (400G)
GPU Server #1 GPU Server #2 GPU Server #3 GPU Server #32 Converged Storage Frontend
Op�on 2: AIS800-32 series switch 800G to 2x 400G breakout cables
10 11